

是什么
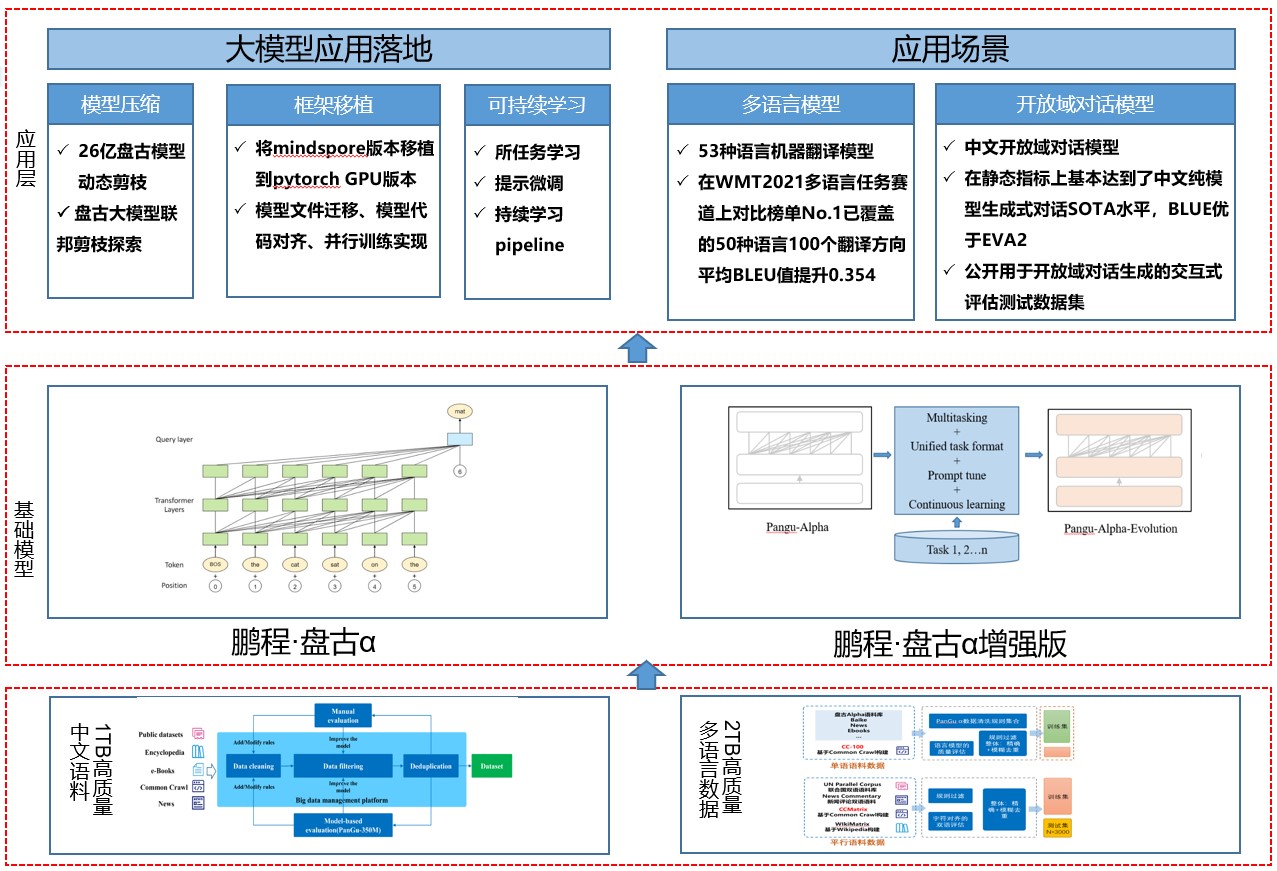
鹏程·盘古α是由鹏城实验室为首的联合攻关技术团队,基于国产芯片昇腾910的E级智能算力平台-鹏城云脑II,训练出的业界首个2000亿参数以中文为核心的预训练生成语言模型,目前开源了鹏程·盘古α和鹏程·盘古α增强版两个版本,并支持NPU和GPU两个版本。
主要功能
1. 知识问答:能够准确理解问题并提供详细、准确的答案,可用于构建智能问答系统。2. 知识检索:从海量文本中快速准确地检索出相关信息,辅助信息查找和资料收集。3. 知识推理:依据给定的知识和条件进行逻辑推理,解决复杂的逻辑问题。4. 阅读理解:对输入的文本进行深入理解,回答与文本相关的问题,适用于教育领域的阅读理解测试等。5. 文本生成:可生成新闻稿件、故事创作、文案撰写等各类文本,满足不同的创作需求。6. 小样本学习:具备很强的小样本学习能力,在少量样本数据的情况下也能快速学习并完成任务。
应用场景
1. 智能客服:为用户提供快速、准确的问题解答和服务支持,提升客服效率和质量。2. 内容创作:辅助作家、编辑等进行故事创作、文章撰写、广告文案生成等工作。3. 教育领域:用于智能辅导、阅读理解测试、作业批改等,助力教育智能化。4. 信息检索:帮助用户从大量文本中快速找到所需信息,如学术研究、资料查询等场景。5. 智能写作助手:辅助办公人员进行文档撰写、报告生成等工作,提高写作效率。6. 知识图谱构建:通过知识问答、推理等功能,为知识图谱的构建和完善提供支持。
适用人群
1. 自然语言处理领域的研究人员,用于开展相关研究和实验。2. 内容创作者,如作家、文案策划人员等,借助其文本生成能力提升创作效率和质量。3. 企业开发人员,用于构建智能客服、智能写作等应用系统。4. 教育工作者,可应用于教学辅助和智能化教育场景。5. 信息检索需求者,如科研人员、学生等,帮助快速获取相关信息。
常见问题
1. 如何开始使用鹏程·盘古α大模型? 在使用鹏程·盘古α大模型之前,用户首先需要了解模型的基本架构和使用环境,建议查阅相关文档进行初步学习。接着,用户可以通过安装相应的SDK或API接口来搭建开发环境。2. 模型支持的语言和任务有哪些? 鹏程·盘古α大模型支持多种自然语言处理任务,包括文本生成、问答系统、文本分类等,涵盖中文和英文等多种语言。3. 如何进行模型的训练和微调? 用户可以利用自己的数据集对鹏程·盘古α大模型进行微调。首先,需要准备相应格式的数据集,并使用提供的训练工具进行训练。建议根据任务类型调整超参数,以提高模型性能。4. 遇到性能问题时该如何处理? 如果使用过程中遇到性能瓶颈,建议检查计算资源是否足够,同时可尝试优化输入数据和模型参数。此外,参考官方文档中的性能优化建议也能有效提升使用体验。5. 有没有提供技术支持或社区支持? 鹏程·盘古α大模型通常会提供官方技术支持,用户可以通过论坛或客服渠道进行咨询。同时,活跃的社区用户也会分享经验和解决方案。
使用技巧
鹏程·盘古α大模型是一款强大的人工智能工具,能够在自然语言处理、文本生成、对话系统等多个领域提供支持。以下是一些使用技巧:1. **明确任务目标**:在使用鹏程·盘古α大模型之前,确保清晰定义你的任务目标。这有助于模型更好地理解上下文和需求。2. **使用简洁明确的语言**:输入时尽量使用简洁、明确的语言,这样可以减少模型的误解,提高响应质量。3. **分步骤提问**:如果任务较为复杂,建议将其拆分为小步骤,逐步进行提问,以便更准确地获取所需的信息。4. **提供上下文信息**:在需要模型生成较为具体的内容时,提供足够的上下文信息,例如背景资料或相关示例,可以帮助模型输出更准确、更符合预期的结果。5. **利用反复迭代**:模型的响应有时可能并不完美,可以根据输出进行调整和重新提问,通过迭代来优化结果。6. **尝试不同的表达方式**:如果模型未能给出满意的回应,可以尝试改变提问的方式或者使用同义词来提高有效性。通过这些技巧,用户可以更好地利用鹏程·盘古α大模型的潜力,提升工作效率和成果质量。